对于AR/VR,定位用麦克风阵列记录的多个声源是一项重要任务。所以,社区已经为这项任务开发了众多到达方向(DOA)估计方法,包括基于波束成形的方法、子空间方法和到达时延估计方法等等。大多数基于所述方法的算法设计都假设自由场环境。当算法用于更常见的混响环境时,它们的DOA性能会下降。
这是因为在混响环境中,房间反射掩盖了携带DOA信息的直接声音。当然,最近社区开发了数种对混响鲁棒的多扬声器DOA估计方法。一种这样的方法在时频域中处理麦克风信号,并采用直接路径优势(DPD)测试来识别由源的直接声音主导的时频bin。然而,它们假设声源和麦克风阵列都是静止,而在声源和/或麦克风阵列移动的动态环境中,相关算法的研究较少。在动态环境中,声源和/或麦克风阵列的运动可能导致DOA在时间上快速变化。因此,为了准确地追踪DOA,需要在连续DOA估计之间的短间隔。另外,可以使用追踪算法来及时平滑DOA估计。
尽管社区已经开始研究动态环境中的DOA估计和追踪算法是,但它们都没有包括可佩戴麦克风阵列的实验。随着AR应用的普及,这样的场景会越来越流行。所以,以色列本·古里安大学的研究人员探索了可佩戴麦克风阵列在噪声动态环境中的DOA估计问题。
实验使用Easy Communication(EasyCom)数据集进行。DOA估计是使用一种计算效率高的算法计算,它在静态混响环境中具有良好的源定位性能。所述算法结合了DPD测试,并在时频域中运行。团队研究了算法在不同操作参数下的性能和局限性。
团队首先简要介绍了麦克风阵列在每个时频段(t,f)捕获的记录信号的假设模型,然后描述了用于每个bin(t,f)处DOA估计的Local Space Domain Distance(LSDD)算法。
信号模型
假设一个麦克风阵列,其中M个麦克风按照预定义的几何形状排列。接下来,考虑由K个远场源组成的声场,从方向Ψk,K∈ {1,2,…,K}到达。源表示场景中扬声器发出的直接声音,以及物体和房间边界引起的反射(混响)。
在下一步中,通过应用short-time Fourier transform(STFT)将记录的麦克风信号变换到联合时频域。这是通过首先将语音信号分离成长度为δt的短时间间隔来实现。然后将fast Fourier transform(FFT)应用于每个时间段。在预处理步骤之后,麦克风阵列接收的信号可以在STFT域中描述为:

团队提出的DOA估计算法
研究人员提出的新DOA评估算法是使用EasyCom数据集研究LSDD算法性能的结果。LSDD算法不使用关于S(t,f)相对于Θl的行为的任何信息。由于所述信息可能有用,团队建议使用相关过程将其合并,如下所示。对于每个频率f,定义一个由矩阵W表示的理想二维谱,其元素为Wlh≡ W(Θl,Θh),表示第l个转向矢量v(f,Θl)和第h个转向矢量v(f,θh)之间的相似性:
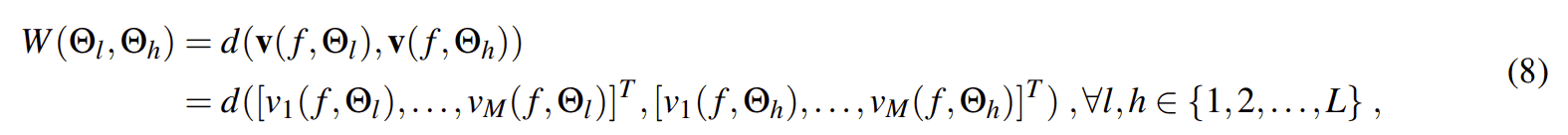
这实际上定义了新的基于方向性的空域距离(dSDD)DOA估计算法。现在使用下列公式计算bin(t、f)的相应DOA估计,
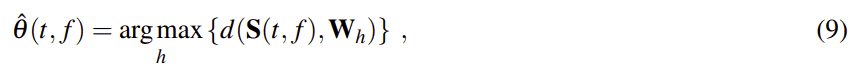
同时,定义相应的DPD测试度量:

(9) 和(10)定义一个(联合)dSDD DOA/DPD算法。应当注意,在理想条件下, LSDD和dSDD这两种算法应该提供相同的估计,因为它们都依赖于同一组导向矢量。然而,提出dSDD的动机是由于对整个函数或向量的比较,对潜在噪点和混响的预期鲁棒性。这与LSDD形成对比,LSDD的DOA估计基于寻找函数中的峰值。另外,与LSDD算法的情况一样,研究人员描述了能量加权dSDD算法(dSDDe)。其中,对于每个bin(t,f),用相应的信号能量对dSDD DPD测试度量进行加权。因此,能量加权DPD测试值为:
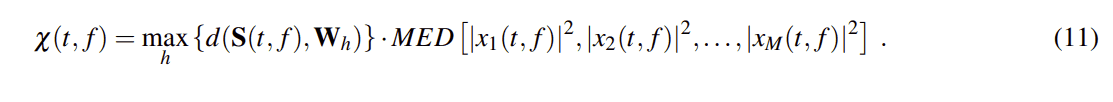
实验研究
团队利用了EasyComm数据集研究LSDD和dSDD的性能。所述数据集的设计目的是分析鸡尾酒会效果,其中音频信号由配备六通道麦克风阵列的增强现实眼镜捕获。数据集包含嘈杂餐厅环境中自然对话的记录。参与者配备了近距离交谈麦克风、摄像头和追踪标记。被试要求在几项任务中进行对话,包括自我介绍、点餐、解谜、玩游戏和阅读句子。

录音同时包含参与者以自我为中心的视频视点。四个麦克风刚性固定在眼镜,两个麦克风放在用户耳朵里。麦克风记录的信号以48kHz的速率采样。使用1024个样本将记录的数据转换为STFT域(≃ 20msec)Hann window,重叠512个样本。STFT域中的麦克风信号用作算法的输入。
DOA/DPD算法的方法评估包括分辨率为5◦的方向搜索。ground truth方位角DOA(Ψk)是从EasyCom数据集获得,并作为时间的函数。总之,团队使用EasyCom数据集进行了一系列三个实验。第一个实验测量了阵列的有效频率范围[flow,fhigh],第二个和第三个实验研究了频率平滑的效果和时间间隔的长度∆T对性能的影响。
DOA估计性能评估如下。对于每个(t,f)bin,绝对误差:

请注意,等式(12) 假设Ψ(t)和θˆ(t,f)都是关于同一轴测量。实际上,Ψ(t)是相对于相对于房间定义的轴测量,而θˆ(t,f)是相对于玻璃的方向测量。因此,在计算ε(t,f)之前,通过合并头部追踪信息将θˆ(t、f)转换为房间的固定轴。
EasyCom数据集涉及语音,这自然限制了感兴趣的频率范围。在实践中,频带通过麦克风阵列产生的混叠效应而减小。对于一个特定的转向向量v(f,Θh)(对应于频率f和方向θh),v(f,Θh)与一组转向向量v∈ {1,2,…,L}使用以下等式计算:
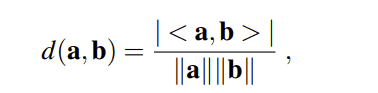
对于导致以下测量所有频率f重复此操作:

目视检查表明,首选频带约为1100−2000Hz。尽管这是一个相对窄的频带,但在这项研究中,它带来了最佳性能。对于未来的工作,研究人员建议扩展低频和高频的工作范围。

DOA误差和频率平滑
频谱S(t,f)在DOA/DPD算法中起着关键作用。特别是,平滑频率S(t,f)有所帮助。研究人员研究了使用长度为(2R+1)的移动平均滤波器在频率上平滑S(t,f)。然后, 对从EasyCom数据集提取的几个1分钟片段进行DOA估计实验.相应的结果如图3所示。

研究人员将获得的结果与LSDD算法的变化,以及LSDDe和dSDDe算法的最佳变化(即无平滑)进行了比较。在低百分比p下,平均绝对误差E(p,∆T) 使用dSDDe算法获得的值约为9◦,低于用LSDD算法获得的值。类似地,用dSDDe算法获得的平均命中率比用LSDD算法获得高大约5%。
DOA误差和时间间隔∆T
时间间隔的选择∆T可能与数据集的动态性质直接相关。通常,希望使用值∆T足够小,使得环境可以认为是间隔内的空间静止。但如果∆T太小,DOA性能可能会降低。在这个实验中,团队调查了数个值:(a)∆T=200毫秒;(b)∆T=300毫秒和(c)∆T=500毫秒。
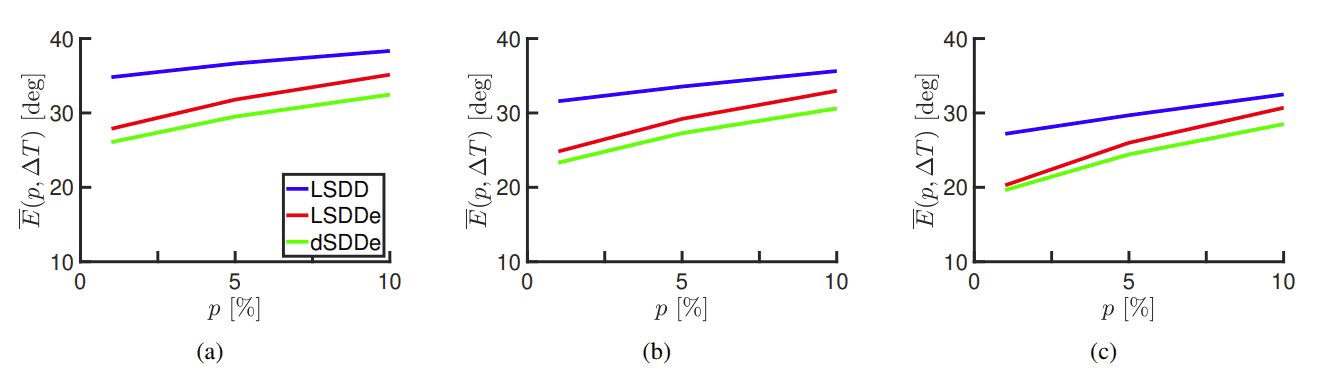
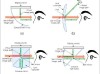
DOA/DPD算法使用了最佳频率平滑。在上图中,随着∆T增加,性能得到持续显著改进。在∆T=500毫秒。当p=1%时,dSDDe给出了平均绝对DOA误差E≈ 20◦ 。与图3相似,dSDDe的性能最好,LSDD的性能最差。

上图说明了dSDDe算法的性能以及几个实验数据值的时间线。ground truth方向使用粗虚线表示。麦克风阵列的方向用粗红线标记。
相关论文:Study of speaker localization under dynamic and reverberant environments
总的来说,以色列本·古里安大学的研究主要是根据EasyCom数据集进行了三次DOA估计实验。相关的初步实验表明: